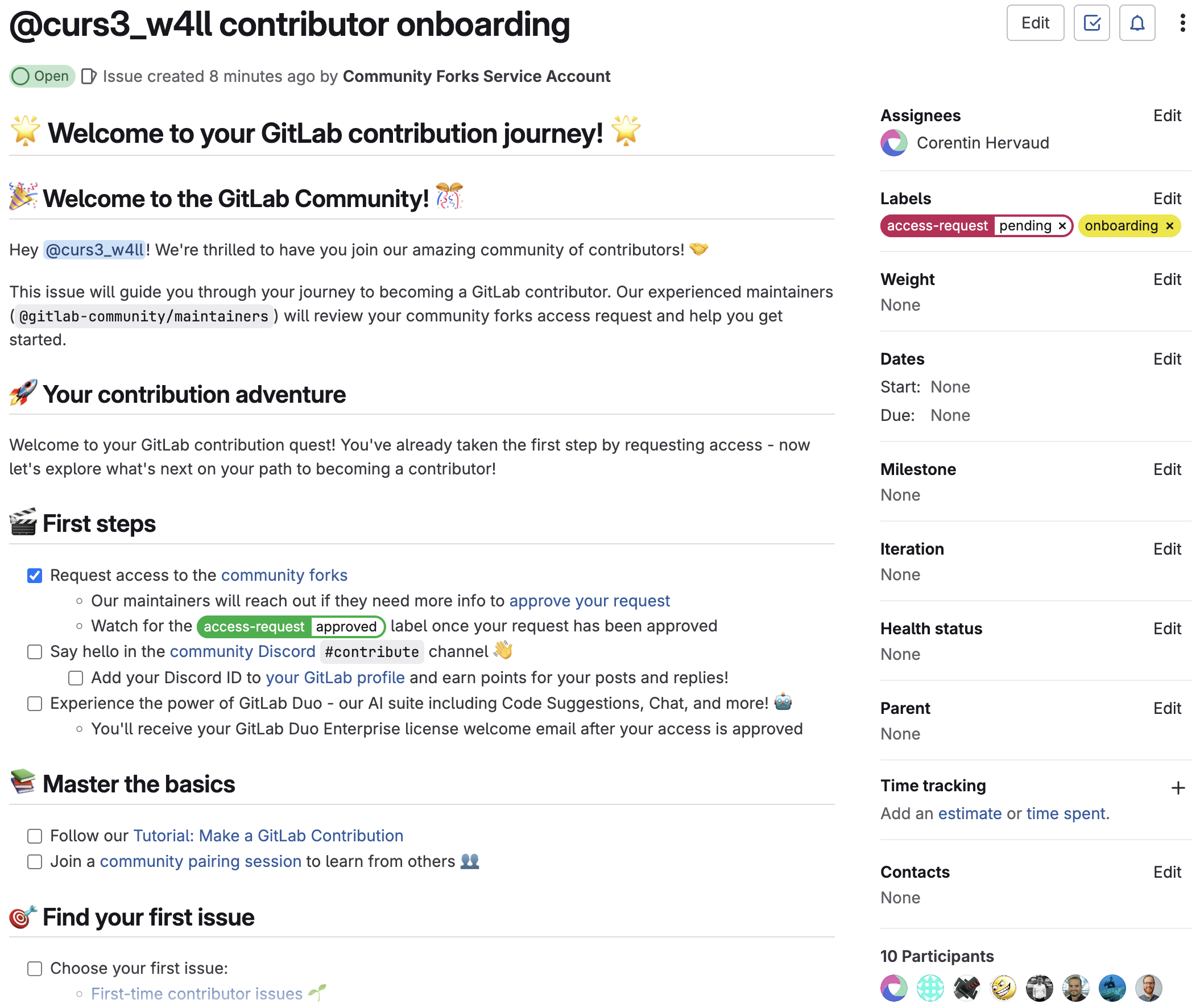
Bei GitLab gestalten wir die Zukunft der Software-Entwicklung neu als Zusammenarbeit zwischen Menschen und KI. Entwickler(innen) konzentrieren sich auf die Lösung technischer, komplexer Probleme und treiben Innovationen voran, während KI-Agenten die routinemäßigen, sich wiederholenden Aufgaben übernehmen, die den Fortschritt verlangsamen. Entwickler(innen) sind frei, neue Ideen im Code zu deutlich geringeren Kosten zu erkunden, Bug-Backlogs gehören der Vergangenheit an, und die Nutzer(innen) der von dir erstellten Software genießen eine benutzerfreundlichere, zuverlässigere und sicherere Erfahrung. Das ist kein ferner Traum. Wir bauen diese Realität schon heute. Sie heißt GitLab Duo Agent Platform.
Was ist GitLab Duo Agent Platform?
GitLab Duo Agent Platform ist unsere DevSecOps-Orchestrierungsplattform der nächsten Generation, welche entwickelt wurde, um die asynchrone Zusammenarbeit zwischen Entwickler(innen) und KI-Agenten zu ermöglichen. Sie wird deinen Entwicklungsworkflow von isolierten linearen Prozessen in eine dynamische Zusammenarbeit verwandeln, bei der spezialisierte KI-Agenten in jeder Phase des Software-Entwicklungslebenszyklus an deiner Seite und mit deinem Team arbeiten. Es wird so sein, als hättest du ein unbegrenztes Team von Kolleg(inn)en zur Verfügung.
Stell dir vor, du delegierst eine komplexe Refaktorierungsaufgabe an einen Software-Entwickler-Agenten, während gleichzeitig ein Sicherheitsanalyse-Agent nach Schwachstellen sucht und ein Deep-Research-Agent den Fortschritt über deine Repository-Historie hinweg analysiert. All dies geschieht parallel, nahtlos orchestriert innerhalb von GitLab.
Heute kündigen wir die Einführung der ersten Public Beta von GitLab Duo Agent Platform für GitLab.com und selbstverwaltete GitLab Premium- und Ultimate-Kund(inn)en an. Dies ist nur die erste einer Reihe von Updates, die verbessern werden, wie Software geplant, erstellt, verifiziert und bereitgestellt wird, während wir menschlichen Einfallsreichtum durch intelligente Automatisierung verstärken.
Diese erste Beta konzentriert sich auf die Freischaltung der IDE-Erfahrung über die GitLab VS Code-Erweiterung und das JetBrains IDEs-Plugin; nächsten Monat planen wir, die Duo Agent Platform-Erfahrung in die GitLab-Anwendung zu bringen und unsere IDE-Unterstützung zu erweitern.
Lass mich ein wenig mehr über unsere Vision für die Roadmap von heute bis zur allgemeinen Verfügbarkeit, die für später in diesem Jahr geplant ist, berichten. Details zur ersten Beta findest du unten.
Schau dir dieses Video an oder lies weiter, um zu erfahren, was jetzt verfügbar ist und was demnächst kommen wird. Wenn du dann bereit bist, mit Duo Agent Platform zu arbeiten, erfährst du hier, wie das mit der Public Beta geht.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1101993507?title=0&byline=0&portrait=0&badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="GitLab Agent Platform Beta Launch_071625_MP_v2"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
GitLabs einzigartige Position als Orchestrierungsplattform
GitLab steht im Mittelpunkt des Entwicklungslebenszyklus als System of Record für Engineering-Teams und orchestriert die gesamte Reise vom Konzept zur Produktion für über 50 Millionen registrierte Nutzer(innen), einschließlich der Hälfte der Fortune 500 über alle Geografien hinweg. Dies umfasst über 10.000 zahlende Kund(inn)en in allen Segmenten und Branchen, einschließlich öffentlicher Institutionen.
Dies gibt GitLab etwas, was kein Wettbewerber bieten kann: ein umfassendes Verständnis von allem, was es braucht, um Software zu liefern. Wir bringen deine Projektpläne, Code, Testläufe, Sicherheitsscans, Compliance-Prüfungen und CI/CD-Konfigurationen zusammen, um nicht nur dein Team zu unterstützen, sondern auch die Zusammenarbeit mit KI-Agenten zu orchestrieren, die du kontrollierst.
Als intelligente, einheitliche DevSecOps-Plattform speichert GitLab den gesamten Kontext deiner Software-Engineering-Praxis an einem Ort. Wir werden diese einheitlichen Daten über unseren Knowledge Graph KI-Agenten zugänglich machen. Jeder Agent, den wir erstellen, hat automatischen Zugriff auf diesen SDLC-verbundenen Datensatz und bietet einen reichhaltigen Kontext, sodass Agenten fundierte Empfehlungen abgeben und Maßnahmen ergreifen können, die deinen organisatorischen Standards entsprechen.
Hier ist ein Beispiel für diesen Vorteil in Aktion. Hast du jemals versucht herauszufinden, wie genau ein Projekt über Dutzende, wenn nicht Hunderte von Stories und Issues verläuft, die von allen beteiligten Entwickler(inne)n bearbeitet werden? Unser Deep Research Agent nutzt den GitLab Knowledge Graph und semantische Suchfunktionen, um dein Epic und alle damit verbundenen Issues zu durchsuchen, die zugehörige Codebasis und den umgebenden Kontext zu erkunden. Er korreliert schnell Informationen über deine Repositories, Merge Requests und Deployment-Historie hinweg. Dies liefert kritische Einblicke, die eigenständige Tools nicht bieten können und die menschliche Entwickler(innen) Stunden kosten würden, um sie zu entdecken.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1101998114?title=0&byline=0&portrait=0&badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="Deep Research Demo_071625_MP_v1"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
Unsere strategische Entwicklung von KI-Features zur Agenten-Orchestrierung
GitLab Duo begann als Add-on, das generative KI zu Entwickler(inne)n über Duo Pro und Enterprise brachte. Mit GitLab 18.0 ist es jetzt in die Plattform integriert. Wir haben Duo Agentic Chat und Code Suggestions für alle Premium- und Ultimate-Nutzer(innen) freigeschaltet, und jetzt bieten wir sofortigen Zugang zu Duo Agent Platform.
Wir haben die Engineering-Investitionen erhöht und beschleunigen die Bereitstellung, wobei jeden Monat leistungsstarke neue KI-Features landen. Aber wir bauen nicht nur einen weiteren Coding-Assistenten. GitLab Duo wird zu einer Agenten-Orchestrierungsplattform, auf der du KI-Agenten erstellen, anpassen und bereitstellen kannst, die an deiner Seite arbeiten und problemlos mit anderen Systemen interoperieren, was die Produktivität dramatisch steigert.
„GitLab Duo Agent Platform verbessert unseren Entwicklungsworkflow mit KI, die unsere Codebasis und unsere Organisation wirklich versteht. GitLab Duo KI-Agenten in unserem System of Record für Code, Tests, CI/CD und den gesamten Software-Entwicklungslebenszyklus eingebettet zu haben, steigert Produktivität, Geschwindigkeit und Effizienz. Die Agenten sind zu echten Mitarbeitern unserer Teams geworden, und ihre Fähigkeit, Absichten zu verstehen, Probleme zu zerlegen und Maßnahmen zu ergreifen, befreit unsere Entwickler(innen), sich den aufregenden, innovativen Arbeiten zu widmen, die sie lieben." - Bal Kang, Engineering Platform Lead bei NatWest
Agenten, die sofort funktionieren
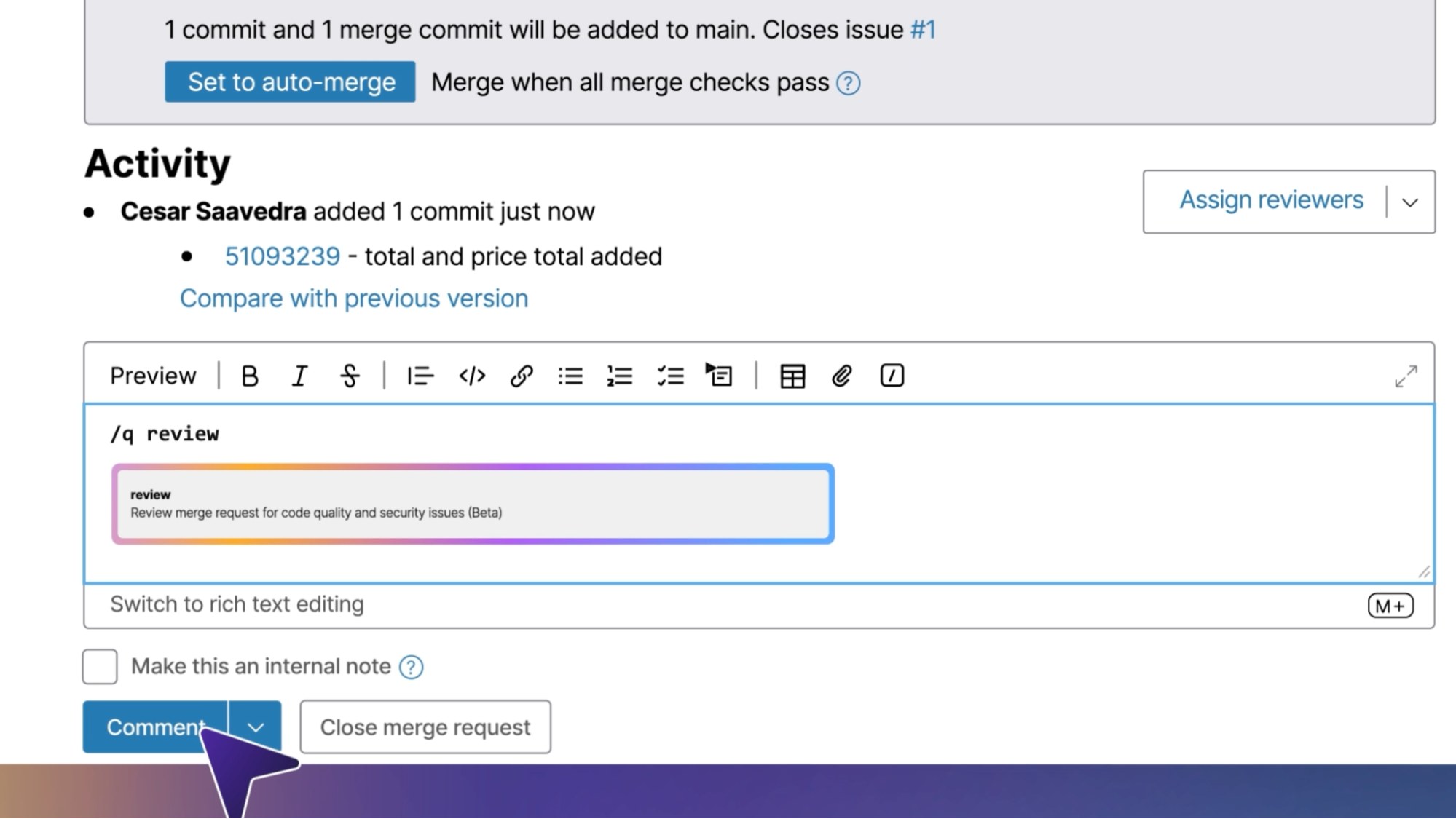
Wir führen Agenten ein, die vertraute Teamrollen widerspiegeln. Diese Agenten können in GitLab suchen, lesen, erstellen und vorhandene Artefakte ändern. Denk an diese als Agenten, mit denen du einzeln interagieren kannst, die auch als Bausteine fungieren, die du anpassen kannst, um deine eigenen Agenten zu erstellen. Wie deine Teammitglieder haben Agenten definierte Spezialisierungen, wie Softwareentwicklung, Testen oder technisches Schreiben. Als Spezialisten nutzen sie den richtigen Kontext und die richtigen Tools, um konsequent die gleichen Arten von Aufgaben zu erledigen, wo immer sie eingesetzt werden.
Hier sind einige der Agenten, die wir heute bauen:
- Chat-Agent (jetzt in Beta): Nimmt Anfragen in natürlicher Sprache entgegen, um dem Nutzer Informationen und Kontext bereitzustellen. Kann allgemeine Entwicklungsaufgaben ausführen, wie das Lesen von Issues oder Code-Diffs. Als Beispiel kannst du Chat bitten, einen fehlgeschlagenen Job zu debuggen, indem du die Job-URL bereitstellst.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1101953504?title=0&byline=0&portrait=0&badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="agentic-chat-in-web-ui-demo_Update V1"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script> <p></p>
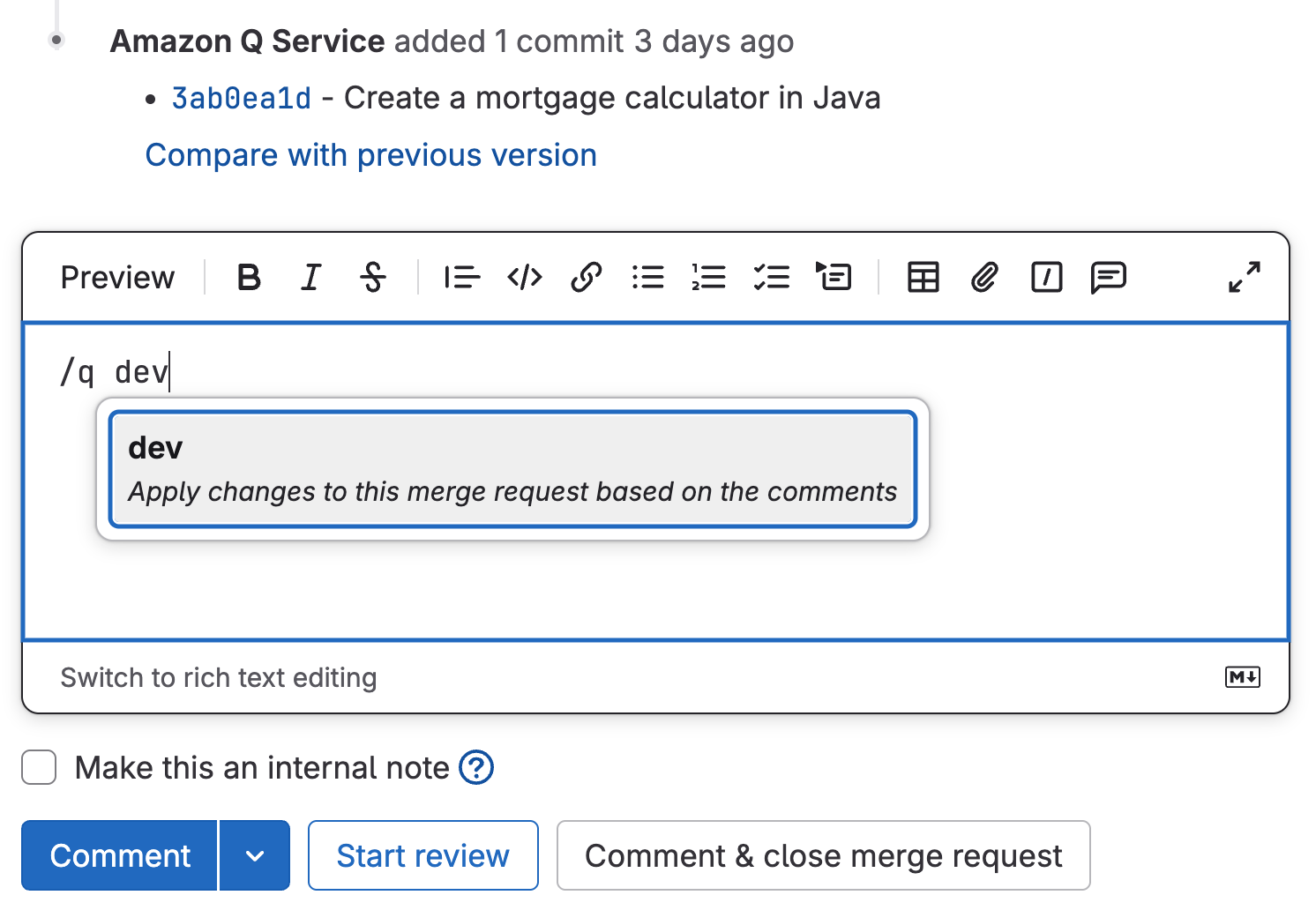
- Software-Entwickler-Agent (jetzt in Beta): Arbeitet an zugewiesenen Elementen, indem er Code-Änderungen in virtuellen Entwicklungsumgebungen erstellt und Merge Requests zur Überprüfung öffnet.
- Produktplanungs-Agent: Priorisiert Produkt-Backlogs, weist Arbeitselemente menschlichen und agentischen Teammitgliedern zu und liefert Projekt-Updates über festgelegte Zeiträume.
- Software-Test-Ingenieur-Agent: Testet neue Code-Beiträge auf Bugs und validiert, ob gemeldete Probleme gelöst wurden.
- Code-Review-Agent: Führt Code-Reviews nach Teamstandards durch, identifiziert Qualitäts- und Sicherheitsprobleme und kann Code mergen, wenn er bereit ist.
- Plattform-Ingenieur-Agent: Überwacht GitLab-Deployments, einschließlich GitLab Runners, verfolgt die CI/CD-Pipeline-Gesundheit und meldet Performance-Probleme an menschliche Plattform-Engineering-Teams.
- Sicherheitsanalyse-Agent: Findet Schwachstellen in Codebasen und bereitgestellten Anwendungen und implementiert Code- und Konfigurationsänderungen, um Sicherheitsschwächen zu beheben.
- Deployment-Ingenieur-Agent: Stellt Updates in der Produktion bereit, überwacht ungewöhnliches Verhalten und macht Änderungen rückgängig, die sich auf die Anwendungsleistung oder -sicherheit auswirken.
- Deep-Research-Agent: Führt umfassende, quellenübergreifende Analysen über dein gesamtes Entwicklungsökosystem durch.
Was diese Agenten leistungsstark macht, ist ihr nativer Zugriff auf GitLabs umfassendes Toolkit. Heute haben wir über 25 Tools, von Issues und Epics bis zu Merge Requests und Dokumentation, mit mehr in Sicht. Im Gegensatz zu externen KI-Tools, die mit begrenztem Kontext arbeiten, arbeiten unsere Agenten als echte Teammitglieder mit vollständigen Plattformberechtigungen unter deiner Aufsicht.
In den kommenden Monaten wirst du auch in der Lage sein, diese Agenten zu modifizieren, um den Bedürfnissen deiner Organisation gerecht zu werden. Zum Beispiel wirst du spezifizieren können, dass ein Software-Test-Ingenieur-Agent Best Practices für ein bestimmtes Framework oder eine bestimmte Methodik befolgt, seine Spezialisierung vertieft und ihn zu einem noch wertvolleren Teammitglied macht.
Flows orchestrieren komplexe Agenten-Aufgaben
Zusätzlich zu einzelnen Agenten führen wir Agenten-Flows ein. Betrachte diese als komplexere Workflows, die mehrere Agenten mit vorgefertigten Anweisungen, Schritten und Aktionen für eine bestimmte Aufgabe umfassen können, die autonom ausgeführt werden kann.
Während du Flows für grundlegende Aufgaben erstellen kannst, die für Einzelpersonen üblich sind, brillieren sie wirklich, wenn sie auf komplexe, spezialisierte Aufgaben angewendet werden, die normalerweise Stunden an Koordination und Aufwand erfordern würden. Flows helfen dir, komplexe Aufgaben schneller zu erledigen und in vielen Fällen asynchron ohne menschliche Intervention.
Flows haben spezifische Trigger für die Ausführung. Jeder Flow enthält eine Reihe von Schritten, und jeder Schritt hat detaillierte Anweisungen, die einem spezialisierten Agenten sagen, was zu tun ist. Dieser granulare Ansatz ermöglicht es dir, den Agenten im Flow präzise Anweisungen zu geben. Durch die Definition von Anweisungen mit mehr Details und die Einrichtung strukturierter Entscheidungspunkte können Flows helfen, die inhärente Variabilität in KI-Antworten zu lösen und gleichzeitig die Notwendigkeit zu eliminieren, wiederholt die gleichen Anforderungen zu spezifizieren, was konsistentere und vorhersagbarere Ergebnisse ohne Benutzerkonfiguration freischaltet.
Hier sind einige Beispiele für sofort einsatzbereite Flows, die wir bauen:
Software-Entwicklungs-Flow (jetzt in Beta): Orchestriert mehrere Agenten, um Code-Änderungen End-to-End zu planen, zu implementieren und zu testen, und hilft dabei zu transformieren, wie Teams Features vom Konzept zur Produktion liefern.
Issue-to-MR-Flow: Konvertiert automatisch Issues in umsetzbare Merge Requests, indem Agenten koordiniert werden, um Anforderungen zu analysieren, umfassende Implementierungspläne vorzubereiten und Code zu generieren.
CI-Datei-Konvertierungs-Flow: Vereinfacht Migrations-Workflows, indem Agenten bestehende CI/CD-Konfigurationen analysieren und sie intelligent in das GitLab CI-Format mit vollständiger Pipeline-Kompatibilität konvertieren.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1101941425?title=0&byline=0&portrait=0&badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="jenkins-to-gitlab-cicd-for-blog"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script> <p></p>
Such- und Ersetzungs-Flow: Entdeckt und transformiert Code-Muster über Codebasen hinweg, indem Projektstrukturen systematisch analysiert, Optimierungsmöglichkeiten identifiziert und präzise Ersetzungen ausgeführt werden.
Incident-Response- und Root-Cause-Analyse-Flow: Orchestriert die Incident-Response durch Korrelation von Systemdaten, Koordination spezialisierter Agenten für die Root-Cause-Analyse und Ausführung genehmigter Abhilfemaßnahmen, während menschliche Stakeholder während des gesamten Lösungsprozesses informiert bleiben.
Hier verfolgt GitLab Duo Agent Platform einen wirklich einzigartigen Ansatz im Vergleich zu anderen KI-Lösungen. Wir geben dir nicht nur vorgefertigte Agenten. Wir geben dir auch die Möglichkeit, Agenten-Flows zu erstellen, anzupassen und zu teilen, die perfekt zu deinen individuellen und organisatorischen Bedürfnissen passen. Und mit Flows kannst du dann Agenten einen spezifischen Ausführungsplan für allgemeine und komplexe Aufgaben geben.
Wir glauben, dass dieser Ansatz leistungsstärker ist als spezialisierte Agenten zu bauen, wie es unsere Wettbewerber tun, denn jede Organisation hat unterschiedliche Workflows, Codierungsstandards, Sicherheitsanforderungen und Geschäftslogik. Generische KI-Tools können deinen spezifischen Kontext nicht verstehen, aber GitLab Duo Agent Platform wird so angepasst werden können, dass sie genau so funktioniert, wie dein Team arbeitet.
Warum Agenten und Agenten-Flows in GitLab Duo Agent Platform bauen?
Es geht schnell. Du kannst Agenten und komplexe Agenten-Flows in Duo Agent Platform schnell und einfach mit einem schnellen, deklarativen Erweiterbarkeitsmodell und UI-Unterstützung erstellen.
Integrierte Rechenleistung. Mit Duo Agent Platform musst du dich nicht mehr um den Aufwand kümmern, deine eigene Infrastruktur für Agenten aufzubauen: Rechenleistung, Netzwerk und Speicher sind alle integriert.
SDLC-Events. Deine Agenten können automatisch bei gängigen Ereignissen aufgerufen werden: defekte Pipeline, fehlgeschlagenes Deployment, erstelltes Issue usw.
Sofortiger Zugriff. Du kannst mit deinen Agenten überall in GitLab oder unserem IDE-Plugin interagieren: weise ihnen Issues zu, @erwähne sie in Kommentaren und chatte mit ihnen überall, wo Duo Chat verfügbar ist.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1102029239?badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="assigning an agent an issue"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script> <p></p>
Unterstützung integrierter und benutzerdefinierter Modelle. Deine Agenten haben automatischen Zugriff auf alle von uns unterstützten Modelle, und Nutzer(innen) können spezifische Modelle für spezifische Aufgaben auswählen. Wenn du Duo Agent Platform mit deinem eigenen selbst gehosteten Modell verbinden möchtest, kannst du das auch tun!
Model Context Protocol (MCP) Endpunkte. Jeder Agent und Flow kann über native MCP-Endpunkte aufgerufen oder ausgelöst werden, sodass du dich von überall aus mit deinen Agenten und Flows verbinden und zusammenarbeiten kannst, einschließlich beliebter Tools wie Claude Code, Cursor, Copilot und Windsurf.
Observability und Sicherheit. Schließlich bieten wir integrierte Observability und Nutzungs-Dashboards, damit du genau sehen kannst, wer, wo, was und wann Agenten in deinem Namen Aktionen durchgeführt haben.
Eine von der Community getriebene Zukunft
Community-Beiträge haben lange Zeit GitLabs Innovation und Softwareentwicklung angetrieben. Wir freuen uns, mit unserer Community bei der Einführung des KI-Katalogs zusammenzuarbeiten. Der KI-Katalog ermöglicht es dir, Agenten und Flows innerhalb deiner Organisation und im gesamten GitLab-Ökosystem in unserer kommenden Beta zu erstellen und zu teilen.
Wir glauben, dass die wertvollsten KI-Anwendungen wahrscheinlich von dir, unserer Community, entstehen werden, dank deiner täglichen Anwendung von GitLab Duo Agent Platform zur Lösung zahlreicher realer Anwendungsfälle. Durch die Ermöglichung des nahtlosen Teilens von Agenten und Flows schaffen wir einen Netzwerkeffekt, bei dem jeder Beitrag die kollektive Intelligenz und den Wert der Plattform erhöht. Im Laufe der Zeit glauben wir, dass die wertvollsten Anwendungsfälle von Agent Platform aus unserer florierenden GitLab-Community kommen werden.

Heute verfügbar in GitLab Duo Agent Platform in Public Beta
Die Public Beta von GitLab Duo Agent Platform ist jetzt für Premium- und Ultimate-Kund(inn)en mit diesen Funktionen verfügbar:
Software-Entwicklungs-Flow: Unser erster Flow orchestriert Agenten beim Sammeln umfassenden Kontexts, beim Klären von Unklarheiten mit menschlichen Entwickler(inne)n und beim Ausführen strategischer Pläne, um präzise Änderungen an deiner Codebasis und deinem Repository vorzunehmen. Er nutzt dein gesamtes Projekt, einschließlich seiner Struktur, Codebasis und Historie, zusammen mit zusätzlichem Kontext wie GitLab-Issues oder Merge Requests, um die Produktivität der Entwickler(innen) zu steigern.
Neue verfügbare Agenten-Tools: Agenten haben jetzt Zugriff auf mehrere Tools, um ihre Arbeit zu erledigen, darunter:
- Dateisystem (Lesen, Erstellen, Bearbeiten, Dateien finden, Auflisten, Grep)
- Befehlszeile ausführen*
- Issues (Auflisten, Abrufen, Kommentare abrufen, Bearbeiten*, Erstellen*, Kommentare hinzufügen/aktualisieren*)
- Epics (Abrufen, Kommentare abrufen)
- MR (Abrufen, Kommentare abrufen, Diff abrufen, Erstellen, Aktualisieren)
- Pipeline (Job-Logs, Pipeline-Fehler)
- Projekt (Abrufen, Datei abrufen)
- Commits (Abrufen, Auflisten, Kommentare abrufen, Diff abrufen)
- Suche (Issue-Suche)
- Secure (Schwachstellen auflisten)
- Dokumentationssuche *=Erfordert Benutzergenehmigung
GitLab Duo Agentic Chat in der IDE: Duo Agentic Chat verwandelt die Chat-Erfahrung von einem passiven Q&A-Tool in einen aktiven Entwicklungspartner direkt in deiner IDE.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1101953477?title=0&byline=0&portrait=0&badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="agentic-ai-launch-video_Updated V1"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
- Iteratives Feedback und Chat-Verlauf: Duo Agentic Chat unterstützt jetzt Chat-Verlauf und iteratives Feedback und verwandelt den Agenten in einen zustandsbehafteten, gesprächsfähigen Partner. Dies fördert Vertrauen und ermöglicht es Entwickler(inne)n, komplexere Aufgaben zu delegieren und korrigierende Anleitung zu bieten.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1101743173?title=0&byline=0&portrait=0&badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="agentic-chat-history"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
- Optimierte Delegation mit Slash-Befehlen: Erweiterte, leistungsstärkere Slash-Befehle wie /explain, /tests und /include erstellen eine „Delegationssprache" für schnelle und präzise Absichten. Der /include-Befehl ermöglicht die explizite Injektion von Kontext aus bestimmten Dateien, offenen Issues, Merge Requests oder Abhängigkeiten direkt in den Arbeitsspeicher des Agenten, macht den Agenten leistungsfähiger und lehrt Nutzer(innen), wie sie optimalen Kontext für qualitativ hochwertige Antworten bereitstellen.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1101743187?title=0&byline=0&portrait=0&badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="include-agentic-chat-jc-voiceover"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
- Personalisierung durch benutzerdefinierte Regeln: Neue benutzerdefinierte Regeln ermöglichen es Entwickler(inne)n, das Agentenverhalten an individuelle und Teampräferenzen anzupassen, indem sie natürliche Sprache verwenden, zum Beispiel Entwicklungs-Styleguides. Dieser grundlegende Mechanismus formt die Persönlichkeit des Agenten zu einem personalisierten Assistenten und entwickelt sich zu spezialisierten Agenten basierend auf benutzerdefinierten Präferenzen und organisatorischen Richtlinien.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1101743179?title=0&byline=0&portrait=0&badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="custom-rules-with-jc-voiceover"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
- Unterstützung für GitLab Duo Agentic Chat in JetBrains IDE: Um Entwickler(innen) dort zu treffen, wo sie arbeiten, haben wir die Unterstützung von Duo Agentic Chat auf die JetBrains-Familie von IDEs erweitert, einschließlich IntelliJ, PyCharm, GoLand und Webstorm. Dies ergänzt unsere bestehende Unterstützung für VS Code. Bestehende Nutzer(innen) erhalten automatisch agentische Funktionen, während neue Nutzer(innen) das Plugin vom JetBrains Marketplace installieren können.
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1101743193?title=0&byline=0&portrait=0&badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="jetbrains-support-jc-voiceover"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
- MCP-Client-Unterstützung: Duo Agentic Chat kann jetzt als MCP-Client fungieren und sich mit remote und lokal laufenden MCP-Servern verbinden.
Diese Fähigkeit ermöglicht es dem Agenten, sich mit Systemen jenseits von GitLab wie Jira, ServiceNow und ZenDesk zu verbinden, um Kontext zu sammeln oder Aktionen durchzuführen. Jeder Service, der sich über MCP exponiert, kann jetzt Teil des Skillsets des Agenten werden. Der offizielle GitLab MCP-Server kommt bald!
<div style="padding:56.25% 0 0 0;position:relative;"><iframe src="https://player.vimeo.com/video/1101743202?title=0&byline=0&portrait=0&badge=0&autopause=0&player_id=0&app_id=58479" frameborder="0" allow="autoplay; fullscreen; picture-in-picture; clipboard-write; encrypted-media; web-share" referrerpolicy="strict-origin-when-cross-origin" style="position:absolute;top:0;left:0;width:100%;height:100%;" title="McpDemo"></iframe></div><script src="https://player.vimeo.com/api/player.js"></script>
- GitLab Duo Agentic Chat in der GitLab Web-UI. Duo Agentic Chat ist jetzt auch direkt in der GitLab Web-UI verfügbar. Dieser entscheidende Schritt entwickelt den Agenten von einem Coding-Assistenten zu einem echten DevSecOps-Agenten, da er Zugriff auf reichhaltigen Nicht-Code-Kontext erhält, wie Issues und Merge-Request-Diskussionen, was es ihm ermöglicht, das „Warum" hinter der Arbeit zu verstehen. Über das Verständnis des Kontexts hinaus kann der Agent Änderungen direkt aus der Web-UI vornehmen, wie z.B. automatisch Issue-Status aktualisieren oder Merge-Request-Beschreibungen bearbeiten.
Bald verfügbar in GitLab Duo Agent Platform
In den kommenden Wochen werden wir neue Funktionen für Duo Agent Platform veröffentlichen, einschließlich weiterer sofort einsatzbereiter Agenten und Flows. Diese werden die Plattform in die GitLab-Erfahrung bringen, die du heute liebst, und noch größere Anpassung und Erweiterbarkeit ermöglichen, was die Produktivität für unsere Kund(inn)en verstärkt:

- Integrierte GitLab-Erfahrung: Aufbauend auf den in 18.2 verfügbaren IDE-Erweiterungen erweitern wir Agenten und Flows innerhalb der GitLab-Plattform. Diese tiefere Integration wird die Möglichkeiten erweitern, wie du synchron und asynchron mit Agenten zusammenarbeiten kannst. Du wirst in der Lage sein, Issues direkt an Agenten zuzuweisen, sie in GitLab Duo Chat zu @erwähnen und sie nahtlos von überall in der Anwendung aufzurufen, während die MCP-Konnektivität von deinem bevorzugten Entwicklungstool beibehalten wird. Diese native Integration verwandelt Agenten in echte Entwicklungsteammitglieder, die in ganz GitLab zugänglich sind.
- Agenten-Observability: Da Agenten autonomer werden, bauen wir umfassende Sichtbarkeit in ihre Aktivität auf, während sie durch Flows fortschreiten, was es dir ermöglicht, ihre Entscheidungsprozesse zu überwachen, Ausführungsschritte zu verfolgen und zu verstehen, wie sie deine Entwicklungsherausforderungen interpretieren und darauf reagieren. Diese Transparenz im Agentenverhalten schafft Vertrauen und Zuversicht, während es dir ermöglicht, Workflows zu optimieren, Engpässe zu identifizieren und sicherzustellen, dass Agenten genau wie beabsichtigt funktionieren.
- KI-Katalog: In Anerkennung der Tatsache, dass großartige Lösungen aus Community-Innovation entstehen, werden wir bald die Public Beta unseres KI-Katalogs einführen - ein Marktplatz, der es dir ermöglicht, Duo Agent Platform mit spezialisierten Agenten und Flows zu erweitern, die von GitLab und im Laufe der Zeit von der breiteren Community stammen. Du wirst in der Lage sein, diese Lösungen schnell in GitLab bereitzustellen und dabei den Kontext über deine Projekte und Codebasis hinweg zu nutzen.
- Knowledge Graph: Unter Nutzung von GitLabs einzigartigem Vorteil als System of Record für Quellcode und seinen umgebenden Kontext bauen wir einen umfassenden Knowledge Graph auf, der nicht nur Dateien und Abhängigkeiten über die Codebasis hinweg abbildet, sondern diese Karte auch für Nutzer(innen) navigierbar macht, während KI-Abfragezeiten beschleunigt und die Genauigkeit erhöht wird. Diese Grundlage ermöglicht es GitLab Duo-Agenten, Beziehungen über deine gesamte Entwicklungsumgebung hinweg schnell zu verstehen, von Code-Abhängigkeiten bis zu Deployment-Mustern, und ermöglicht schnellere und präzisere Antworten auf komplexe Fragen.

- Agenten und Flows erstellen und bearbeiten: Im Verständnis, dass jede Organisation einzigartige Workflows und Anforderungen hat, entwickeln wir leistungsstarke Funktionen zur Erstellung und Bearbeitung von Agenten und Flows, die eingeführt werden, wenn der KI-Katalog reift. Du wirst in der Lage sein, Agenten und Flows zu erstellen und zu modifizieren, damit sie genau so funktionieren, wie deine Organisation arbeitet, und eine tiefe Anpassung über Duo Agent Platform hinweg liefern, die qualitativ hochwertigere Ergebnisse und erhöhte Produktivität ermöglicht.

- Offizieller GitLab MCP-Server: In der Erkenntnis, dass Entwickler(innen) über mehrere Tools und Umgebungen hinweg arbeiten, bauen wir einen offiziellen GitLab MCP-Server, der es dir ermöglicht, über MCP auf alle deine Agenten und Flows zuzugreifen. Du wirst in der Lage sein, dich mit deinen Agenten und Flows von überall aus zu verbinden und zusammenzuarbeiten, wo MCP unterstützt wird, einschließlich beliebter Tools wie Claude Code, Cursor, Copilot und Windsurf, was eine nahtlose KI-Zusammenarbeit unabhängig von deiner bevorzugten Entwicklungsumgebung ermöglicht.
- GitLab Duo Agent Platform CLI: Unsere kommende CLI ermöglicht es dir, Agenten aufzurufen und Flows auf der Befehlszeile auszulösen, wobei GitLabs reichhaltiger Kontext über den gesamten Software-Entwicklungslebenszyklus genutzt wird - von Code-Repositories und Merge Requests bis zu CI/CD-Pipelines und Issue-Tracking.
Jetzt loslegen
- GitLab Premium- und Ultimate-Kund(inn)en in GitLab.com- und selbstverwalteten Umgebungen, die GitLab 18.2 verwenden, können Duo Agent Platform sofort nutzen (Beta- und experimentelle Funktionen für GitLab Duo müssen aktiviert sein).
- Nutzer(innen) sollten die VS Code-Erweiterung oder das JetBrains IDEs-Plugin herunterladen und unserem Leitfaden zur Verwendung von GitLab Duo Agentic Chat folgen, einschließlich der Duo Chat Slash-Befehle.
Neu bei GitLab? Jeder kann an unserer kommenden (englischsprachigen) Technischen Demo teilnehmen, um GitLab Duo Agent Platform in Aktion zu sehen. Um GitLab Duo Agent Platform selbst praktisch zu erleben, melde dich noch heute für eine kostenlose Testversion an.
<small>Dieser Blogbeitrag enthält „zukunftsgerichtete Aussagen" im Sinne von Abschnitt 27A des Securities Act von 1933 in der geänderten Fassung und Abschnitt 21E des Securities Exchange Act von 1934. Obwohl wir glauben, dass die in den zukunftsgerichteten Aussagen in diesem Blogbeitrag zum Ausdruck gebrachten Erwartungen angemessen sind, unterliegen sie bekannten und unbekannten Risiken, Unsicherheiten, Annahmen und anderen Faktoren, die dazu führen können, dass die tatsächlichen Ergebnisse oder Resultate wesentlich von den in den zukunftsgerichteten Aussagen ausgedrückten oder implizierten zukünftigen Ergebnissen oder Resultaten abweichen.
Weitere Informationen zu Risiken, Unsicherheiten und anderen Faktoren, die dazu führen könnten, dass die tatsächlichen Ergebnisse und Resultate wesentlich von den in den zukunftsgerichteten Aussagen in diesem Blogbeitrag enthaltenen oder betrachteten abweichen, finden sich unter der Überschrift „Risikofaktoren" und an anderer Stelle in den Einreichungen und Berichten, die wir bei der Securities and Exchange Commission einreichen. Wir übernehmen keine Verpflichtung, zukunftsgerichtete Aussagen zu aktualisieren oder zu überarbeiten oder über Ereignisse oder Umstände nach dem Datum dieses Blogbeitrags zu berichten oder das Eintreten unvorhergesehener Ereignisse widerzuspiegeln, es sei denn, dies ist gesetzlich vorgeschrieben.</small>
]]>